 第13期 - 公园落叶🍂
第13期 - 公园落叶🍂

封面图来源于清明节去共青森林公园,比起色彩斑澜的花朵,我更喜欢这满地落叶带来的惬意。
学习笔记-算法相关
如何在程序中实现重复执行任务,即两种基本的程序控制结构:迭代、递归。
迭代
迭代(iteration)是一种重复执行某个任务的控制结构。 for 循环:适合在预先知道迭代次数时使用 while 循环:程序每轮都会先检查条件,如果条件为真,则继续执行,否则就结束循环。 for 循环的代码更加紧凑,while 循环更加灵活
嵌套循环: 在一个循环结构内嵌套另一个循环结构, 在这种情况下,函数的操作数量与 n 成正比
递归
递归(recursion)是一种算法策略,通过函数调用自身来解决问题。 递:程序不断深入地调用自身,通常传入更小或更简化的参数,直到达到“终止条件”。 归:触发“终止条件”后,程序从最深层的递归函数开始逐层返回,汇聚每一层的结果。
递归代码主要包含三个要素: 终止条件:用于决定什么时候由“递”转“归”。 递归调用:对应“递”,函数调用自身,通常输入更小或更简化的参数。 返回结果:对应“归”,将当前递归层级的结果返回至上一层。 这个图描述得非常清晰 https://www.hello-algo.com/chapter_computational_complexity/iteration_and_recursion.assets/recursion_sum.png
{kind=link}
调用栈
递归函数每次调用自身时,系统都会为新开启的函数分配内存,以存储局部变量、调用地址和其他信息等。 对于空间:函数的上下文数据都存储在称为“栈帧空间”的内存区域中,直至函数返回后才会被释放。因此,递归通常比迭代更加耗费内存空间。 对于时间:递归调用函数会产生额外的开销。因此递归通常比循环的时间效率更低。
递:当函数被调用时,系统会在“调用栈”上为该函数分配新的栈帧,用于存储函数的局部变量、参数、返回地址等数据。 归:当函数完成执行并返回时,对应的栈帧会被从“调用栈”上移除,恢复之前函数的执行环境。
在实际中,递归深度通常是有限的,过深的递归可能导致栈溢出错误。
迭代:“自下而上”地解决问题。从最基础的步骤开始,然后不断重复或累加这些步骤,直到任务完成。 递归:“自上而下”地解决问题。将原问题分解为更小的子问题,这些子问题和原问题具有相同的形式。接下来将子问题继续分解为更小的子问题,直到基本情况时停止(基本情况的解是已知的)。
上述求和函数为例,设问题 f(n) = 1+2+…+n。
迭代:在循环中模拟求和过程,从 1遍历到 n,每轮执行求和操作,即可求得 f(n)。 递归:将问题分解为子问题 f(n) = n + f(n-1),不断(递归地)分解下去,直至基本情况 f(1) = 1时终止。
尾递归
如果函数在返回前的最后一步才进行递归调用,则该函数可以被编译器或解释器优化,使其在空间效率上与迭代相当。这种情况被称为尾递归(tail recursion)。
普通递归:当函数返回到上一层级的函数后,需要继续执行代码,因此系统需要保存上一层调用的上下文。 尾递归:递归调用是函数返回前的最后一个操作,这意味着函数返回到上一层级后,无须继续执行其他操作,因此系统无须保存上一层函数的上下文。
以计算 1+2+3+…+n为例,我们可以将结果变量 res 设为函数参数,从而实现尾递归:
/* 尾递归 */
function tailRecur(n, res) {
// 终止条件
if (n === 0) return res;
// 尾递归调用
return tailRecur(n - 1, res + n);
}
/* 尾递归 */
function recur(n) {
if (n === 1) return 1;
const res = recur(n - 1);
return n + res;
}
/* 普通递归 */
function recur(n) {
if (n === 1) return 1; // 终止条件
const res = recur(n - 1); // 递:递归调用
return n + res; // 归:返回结果
}普通递归:求和操作是在“归”的过程中执行的,每层返回后都要再执行一次求和操作。 尾递归:求和操作是在“递”的过程中执行的,“归”的过程只需层层返回。
许多编译器或解释器并不支持尾递归优化。例如,Python 默认不支持尾递归优化,因此即使函数是尾递归形式,仍然可能会遇到栈溢出问题。一些函数式编程语言(如Scheme)以及某些现代 JavaScript 引擎(如V8)支持尾递归优化。
当处理与“分治”相关的算法问题时,递归往往比迭代的思路更加直观、代码更加易读。
给定一个斐波那契数列 0,1,1,2,3,5,8,13,…, 求该数列的第 n 个数字 设斐波那契数列的第 n 个数字为 f(n),易得两个结论。 数列的前两个数字为 f(1) = 0 和 f(2) = 1。 数列中的每个数字是前两个数字的和,即 f(n) = f(n-1) + f(n-2) 。 按照递推关系进行递归调用,将前两个数字作为终止条件,便可写出递归代码。调用 fib(n) 即可得到斐波那契数列的第 n 个数字:
/* 斐波那契数列:递归 */
function fib(n) {
// 终止条件 f(1) = 0, f(2) = 1
if (n === 1 || n === 2) return n - 1;
// 递归调用 f(n) = f(n-1) + f(n-2)
const res = fib(n - 1) + fib(n - 2);
// 返回结果 f(n)
return res;
}从一个调用产生了两个调用分支, 不断递归调用下去,最终将产生一棵层数为 n 的递归树(recursion tree)
复杂度排序 O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(2^n) < O(n!)
时间复杂度
如果加法操作 + 需要 1 ns ,乘法操作 * 需要 10 ns ,打印操作 print() 需要 5 ns
function algorithm(n) {
var a = 1; // +1
a += 1; // +1
a *= 2; // +1
// 循环 n 次
for(let i = 0; i < n; i++){ // +1(每轮都执行 i ++)
console.log(0); // +1
}
}T(n) = 3 + 2n 运行时间的增长趋势是线性的,因此它的时间复杂度是线性阶。将线性阶的时间复杂度记为 O(n), 表示函数 T(n) 的渐近上界
函数渐近上界: 若存在正实数 c 使得 T(n) <= c.f(n), 则 f(n) 为 T(n) 的渐近上界,即为 T(n) = O(f(n))
时间复杂度由 T(n) 中最高阶的项来决定。这是因为在 n 趋于无穷大时,最高阶的项将发挥主导作用,其他项的影响都可以忽略。
时间复杂度分析统计的不是算法运行时间,而是算法运行时间随着数据量变大时的增长趋势。
// 算法 A 的时间复杂度:常数阶
function algorithm_A(n) {
console.log(0);
}
// 算法 B 的时间复杂度:线性阶
function algorithm_B(n) {
for (let i = 0; i < n; i++) {
console.log(0);
}
}
// 算法 C 的时间复杂度:常数阶
function algorithm_C(n) {
for (let i = 0; i < 1000000; i++) {
console.log(0);
}
}O(1) 常数阶的操作数量与输入数据大小 n 无关,即不随着 n 的变化而变化。
O(n) 线性阶的操作数量相对于输入数据大小 n 以线性级别增长。线性阶通常出现在单层循环中, 遍历数组和遍历链表等操作的时间复杂度均为 O(n) ,其中 n 为数组或链表的长度
O(n^2) 平方阶的操作数量相对于输入数据大小 n 以平方级别增长。平方阶通常出现在嵌套循环中,外层循环和内层循环的时间复杂度都为 O(n) ,因此总体的时间复杂度为 O(n^2)
O(2^n) 生物学的“细胞分裂”是指数阶增长的典型例子:初始状态为 1 个细胞,分裂一轮后变为 2 个,分裂两轮后变为 4个,以此类推,分裂 n 轮后有 2^n 个细胞。 模拟了细胞分裂的过程,时间复杂度为 O(2^n)
/* 指数阶(循环实现) */
function exponential(n) {
let count = 0,
base = 1;
// 细胞每轮一分为二,形成数列 1, 2, 4, 8, ..., 2^(n-1)
for (let i = 0; i < n; i++) {
// base 从 1 开始,按照指数级别增长:1, 2, 4, 8, ..., 直到达到 2^(n-1)。
// 拿数据找规律去凑函数
for (let j = 0; j < base; j++) {
count++;
}
base *= 2;
}
// count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count;
}
/* 指数阶(递归实现) */
function expRecur(n) {
if (n === 1) return 1;
return expRecur(n - 1) + expRecur(n - 1) + 1;
}指数阶增长非常迅速,在穷举法(暴力搜索、回溯等)中比较常见。对于数据规模较大的问题,指数阶是不可接受的,通常需要使用动态规划或贪心算法等来解决。
O(logn) 与指数阶相反,对数阶反映了“每轮缩减到一半”的情况。设输入数据大小为 n,由于每轮缩减到一半,因此循环次数是 log2n ,即 2^n 的反函数。时间复杂度为 log2n ,简记为 logn
/* 对数阶(循环实现) */
function logarithmic(n) {
let count = 0;
while (n > 1) {
n = n / 2;
count++;
}
return count;
}O(nlogn) 线性对数阶常出现于嵌套循环中,两层循环的时间复杂度分别为 O(logn) 和 O(n) 主流排序算法的时间复杂度通常为 O(nlogn) ,例如快速排序、归并排序、堆排序等。
/* 线性对数阶 */
function linearLogRecur(n) {
if (n <= 1) return 1;
let count = linearLogRecur(n / 2) + linearLogRecur(n / 2);
for (let i = 0; i < n; i++) {
count++;
}
return count;
}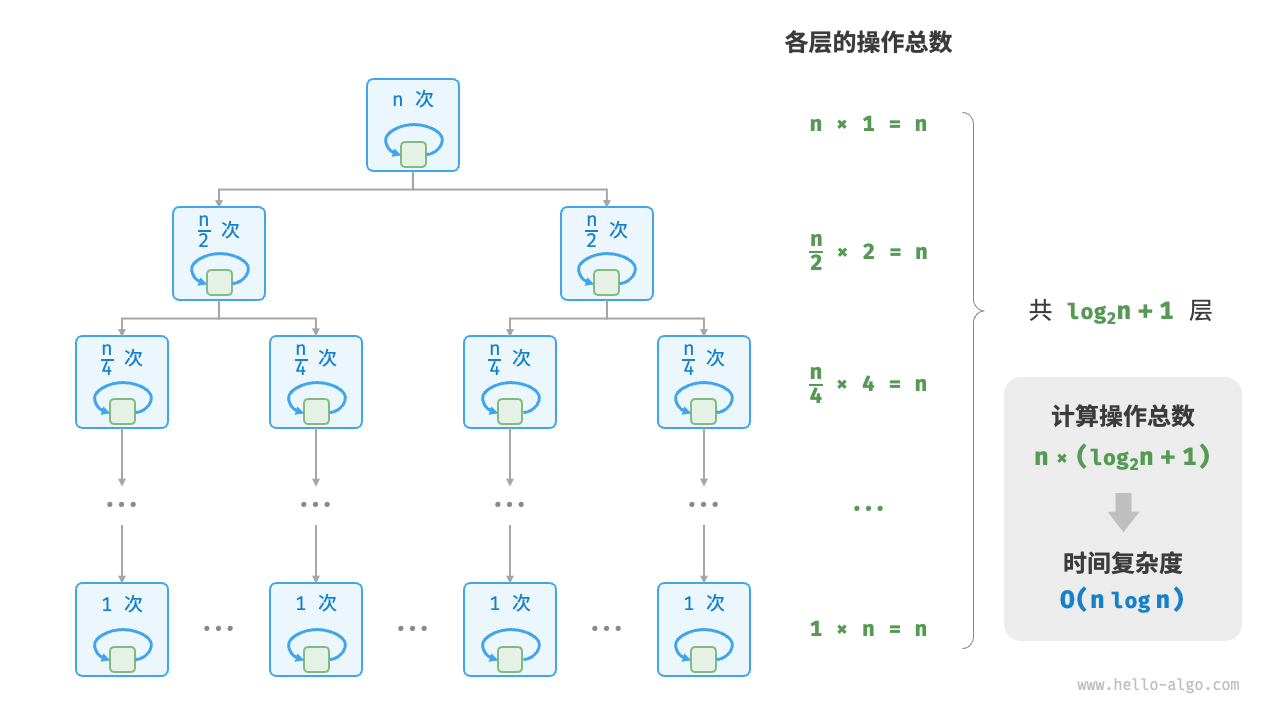{kind=link}
O(!n) 阶乘阶对应数学上的“全排列”问题。给定 n 个互不重复的元素,求其所有可能的排列方案 阶乘通常使用递归实现, 如下 第一层分裂出 n 个,第二层分裂出 n-1 个,以此类推,直至第 n 层时停止分裂:
/* 阶乘阶(递归实现) */
function factorialRecur(n) {
if (n === 0) return 1;
let count = 0;
// 从 1 个分裂出 n 个
// n -> n(n-1) -> n(n-1)(n-2) ... n!
for (let i = 0; i < n; i++) {
count += factorialRecur(n - 1);
}
return count;
}最差、最佳、平均时间复杂度 算法的时间效率往往不是固定的,而是与输入数据的分布有关. 最差时间复杂度”对应函数渐近上界
空间复杂度
空间复杂度即为函数内部所需的最大内存空间。这个内存空间通常是由函数内的变量、数据结构和其它辅助空间(如递归调用的栈空间)所占用的总和。通常情况下,空间复杂度被定义为对于给定问题规模 n,算法在运行过程中所占用的额外内存空间大小。
通常只关注最差空间复杂度,以最差输入数据为准,以算法运行中的峰值内存为准
function algorithm(n) {
const a = 0; // O(1)
const b = new Array(10000); // O(1)
if (n > 10) {
const nums = new Array(n); // O(n)
}
}固定额外空间 O(1):常数阶常见于数量与输入数据大小无关的常量、变量、对象。如果算法在执行过程中需要使用的额外空间是固定不变的,不随输入规模的增加而增加,那么空间复杂度可以表示为一个常数。
线性额外空间 O(n):线性阶常见于元素数量与n成正比的数组、链表、栈、队列等,如果算法所需的额外空间与输入规模成线性关系,通常表示为 O(n),其中 n 表示输入规模。
非线性额外空间 O(n^2):平方阶常见于矩阵和图,元素数量与 n 成平方关系
/* 平方阶(递归实现) */
function quadraticRecur(n) {
if (n <= 0) return 0;
const nums = new Array(n);
console.log(`递归 n = ${n} 中的 nums 长度 = ${nums.length}`);
return quadraticRecur(n - 1);
}如果被递归的函数每次调用都产生 n 个空间,则随着递归深度的增加,空间复杂度将呈平方级增长。在这种情况下,递归深度的每一层都会产生 n 个空间,总的空间占用将会是 O(n^2)。
O(2^n):指数阶常见于二叉树。层数为 n 的“满二叉树”的节点数量为 2^n - 1,占用 O(2^n) 空间
/* 指数阶(建立满二叉树) */
function buildTree(n) {
if (n === 0) return null;
const root = new TreeNode(0); // 根节点
root.left = buildTree(n - 1); // 左子树
root.right = buildTree(n - 1); // 右子树
return root;
}
// 2^0、2^1、2^2、2^3、2^(n-1)... 每一次递归 执行 2^(n-1) 次 相加等于 2^n - 1O(logn) 对数阶常见于分治算法。例如归并排序,输入长度为 n 的数组,每轮递归将数组从中点处划分为两半,形成高度为 logn 的递归树
每次函数调用都会在内存中创建一个函数调用帧(也称为栈帧),用于存储函数的局部变量、参数、返回地址等信息。这些栈帧被依次压入调用栈中。所以当递归调用深度为 log n 时,调用栈的大小也会增长到对数级别。
时间pk空间 理想情况下,我们希望算法的时间复杂度和空间复杂度都能达到最优。降低时间复杂度通常需要以提升空间复杂度为代价,在大多数情况下,时间比空间更宝贵,因此“以空间换时间”通常是更常用的策略。
二叉树
二叉树基本操作
/* 初始化二叉树 */
// 初始化节点
let n1 = new TreeNode(1),
n2 = new TreeNode(2),
n3 = new TreeNode(3),
// 构建节点之间的引用(指针)
n1.left = n2;
n1.right = n3;
/* 插入与删除节点 */
let P = new TreeNode(0);
// 在 n1 -> n2 中间插入节点 P
n1.left = P;
P.left = n2;
// 删除节点 P
n1.left = n2; // n2 是下一层的节点https://www.hello-algo.com/chapter_tree/binary_tree.assets/binary_tree_add_remove.png
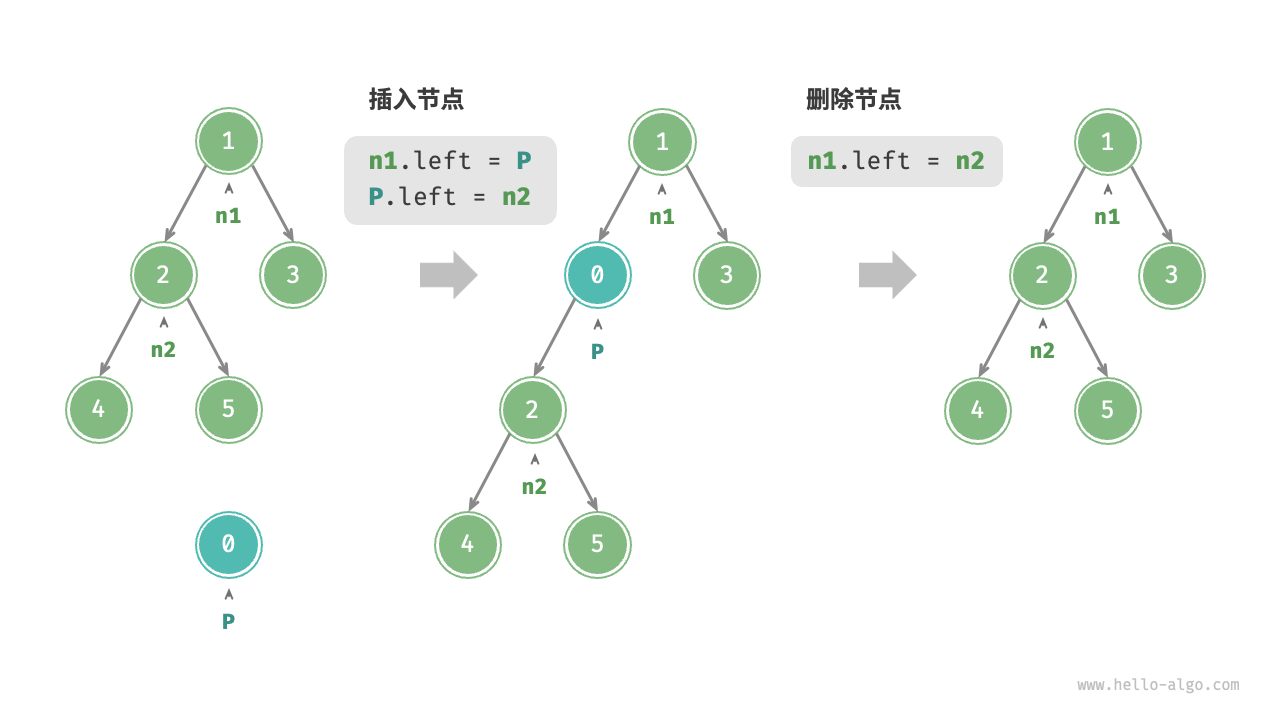{kind=link}
层序遍历
层序遍历(level-order traversal)从顶部到底部逐层遍历二叉树,并在每一层按照从左到右的顺序访问节点。
本质上属于广度优先遍历(breadth-first traversal),也称广度优先搜索(breadth-first search, BFS),它体现了一种“一圈一圈向外扩展”的逐层遍历方式。
广度优先遍历通常借助“队列”来实现。队列遵循“先进先出”的规则
/* 层序遍历 */
function levelOrder(root) {
// 初始化队列,加入根节点
const queue = [root];
// 初始化一个列表,用于保存遍历序列
const list = [];
while (queue.length) {
let node = queue.shift(); // 队列出队
list.push(node.val); // 保存节点值
if (node.left) queue.push(node.left); // 左子节点入队
if (node.right) queue.push(node.right); // 右子节点入队
}
return list;
}前序、中序、后序遍历
前序、中序和后序遍历都属于深度优先遍历(depth-first traversal),也称深度优先搜索(depth-first search, DFS),它体现了一种“先走到尽头,再回溯继续”的遍历方式。 深度优先搜索通常基于递归实现
/* 前序遍历 */
function preOrder(root) {
if (root === null) return;
// 访问优先级:根节点 -> 左子树 -> 右子树
list.push(root.val);
preOrder(root.left);
preOrder(root.right);
}
/* 中序遍历 */
function inOrder(root) {
if (root === null) return;
// 访问优先级:左子树 -> 根节点 -> 右子树
inOrder(root.left);
list.push(root.val);
inOrder(root.right);
}
/* 后序遍历 */
function postOrder(root) {
if (root === null) return;
// 访问优先级:左子树 -> 右子树 -> 根节点
postOrder(root.left);
postOrder(root.right);
list.push(root.val);
}二叉树类型
完美二叉树(perfect binary tree)所有层的节点都被完全填满 完全二叉树(complete binary tree)只有最底层的节点未被填满 平衡二叉树(balanced binary tree)中任意节点的左子树和右子树的高度之差的绝对值不超过 1
二叉搜索树
二叉搜索树(binary search tree)满足: 对于根节点,左子树中所有节点的值 < 根节点的值 < 右子树中所有节点的值; 任意节点的左、右子树也是二叉搜索树
给定目标节点值 num 查找节点 声明一个节点 cur ,从二叉树的根节点 root 出发,循环比较节点值 cur.val 和 num 之间的大小关系 若 cur.val < num ,说明目标节点在 cur 的右子树中,因此执行 cur = cur.right 。 若 cur.val > num ,说明目标节点在 cur 的左子树中,因此执行 cur = cur.left 。 若 cur.val = num ,说明找到目标节点,跳出循环并返回该节点。
二叉搜索树的查找操作与二分查找算法的工作原理一致,每轮排除一半情况
/* 查找节点 */
search(num) {
let cur = this.root;
// 循环查找,越过叶节点后跳出
while (cur !== null) {
// 目标节点在 cur 的右子树中
if (cur.val < num) cur = cur.right;
// 目标节点在 cur 的左子树中
else if (cur.val > num) cur = cur.left;
// 找到目标节点,跳出循环
else break;
}
// 返回目标节点
return cur;
}给定一个待插入元素 num 进行 插入节点 由于二叉搜索树的性质,左小右大 所以待插入的节点,一定是在叶子节点,并且是唯一的位置。
查找插入位置:与查找操作相似,从根节点出发,根据当前节点值和 num 的大小关系循环向下搜索,直到越过叶节点(遍历至 None )时跳出循环。 在该位置插入节点:初始化节点 num ,将该节点置于 None 的位置 若待插入节点在树中已存在,则不执行插入,直接返回(二叉搜索树不允许存在重复节点) 为了实现插入节点,我们需要借助节点 pre 保存上一轮循环的节点。这样在遍历至 None 时,我们可以获取到其父节点,从而完成节点插入操作。
/* 插入节点 */
insert(num) {
// 若树为空,则初始化根节点
if (this.root === null) {
this.root = new TreeNode(num);
return;
}
let cur = this.root,
pre = null;
// 循环查找,越过叶节点后跳出
while (cur !== null) {
// 找到重复节点,直接返回
if (cur.val === num) return;
pre = cur;
// 插入位置在 cur 的右子树中
if (cur.val < num) cur = cur.right;
// 插入位置在 cur 的左子树中
else cur = cur.left;
}
// 插入节点
const node = new TreeNode(num);
if (pre.val < num) pre.right = node;
else pre.left = node;
}删除节点: 与插入节点类似,需要保证在删除操作完成后,二叉搜索树的“左子树 < 根节点 < 右子树”的性质仍然满足。根据目标节点的子节点数量,分 0、1 和 2 三种情况,执行对应的删除节点操作。
- 当待删除节点的度(节点的子节点的数量)为 0 时,表示该节点是叶节点,可以直接删除。
- 当待删除节点的度为 1 时,将待删除节点替换为其子节点
- 当待删除节点的度为 2 时,找到删除节点后还需要重新调整二叉树已保持搜索二叉树的性质